
Hay un tipo de IA que no aprende de libros, sino de la experiencia. Así es como, a base de prueba y error, una máquina logró dominar el juego más complejo del mundo.
Hola, soy Goslen Burgos, y hoy vamos a hablar de un momento que conmocionó al mundo. En marzo de 2016, el legendario Lee Sedol, considerado el mejor jugador de Go del mundo, se sentó frente a un oponente silencioso: un programa de ordenador llamado AlphaGo. El Go es un juego de una complejidad abrumadora, con más movimientos posibles que átomos en el universo conocido. Se le consideraba el pináculo de la intuición humana, imposible de conquistar por una máquina a base de simple cálculo.
Y sin embargo, la máquina ganó.
La pregunta que todos se hicieron fue: ¿cómo es posible? La IA que logró esta hazaña no aprendió estudiando millones de libros de jugadas. No fue programada con las estrategias de los grandes maestros. Aprendió de la misma forma en que tú y yo aprendimos nuestra primera gran habilidad física: como un niño que aprende a andar en bicicleta.
Hoy vamos a explorar esa magia: el Aprendizaje por Refuerzo (Reinforcement Learning).
Una Analogía Sencilla: La IA que Aprende como un Niño en Bicicleta
Olvidemos por un momento los algoritmos y pensemos en la escena más universal de aprendizaje: un niño, una bicicleta y una acera. ¿Cómo aprende ese niño? No hay un manual de instrucciones. Sus padres no le pueden explicar la física del equilibrio con ecuaciones.
El niño aprende a través de un ciclo simple y poderoso:
- El Intento (Acción): El niño se sube a la bicicleta. Su cerebro no sabe qué hacer. Decide empujar el pedal con fuerza. Esa es su primera acción.
- La Retroalimentación (Recompensa o Castigo): La bicicleta se tambalea y cae. El resultado es un raspón en la rodilla (un castigo o «recompensa negativa») y un avance de apenas medio metro (una pequeña «recompensa positiva»).
- El Aprendizaje (Ajuste): El cerebro del niño registra una lección vital: «Esa acción específica, en esa situación, llevó a un mal resultado. No volveré a hacerlo». Su estrategia interna se ajusta.
- La Repetición: El niño lo intenta de nuevo. Esta vez, quizás pedalea más suavemente. Logra avanzar tres metros antes de caer. ¡Mejor resultado! Su cerebro refuerza esa nueva acción: «Esto funciona mejor. Lo haré más a menudo».
A través de cientos de estos ciclos de intento, retroalimentación y ajuste, el niño va construyendo, sin ser consciente de ello, un modelo interno increíblemente complejo sobre el equilibrio, la velocidad y la dirección.
Los 4 Ingredientes Clave del Aprendizaje por Refuerzo
Este proceso, que parece tan natural, se puede descomponer en unos pocos ingredientes clave. Y son exactamente los mismos que usa la IA:
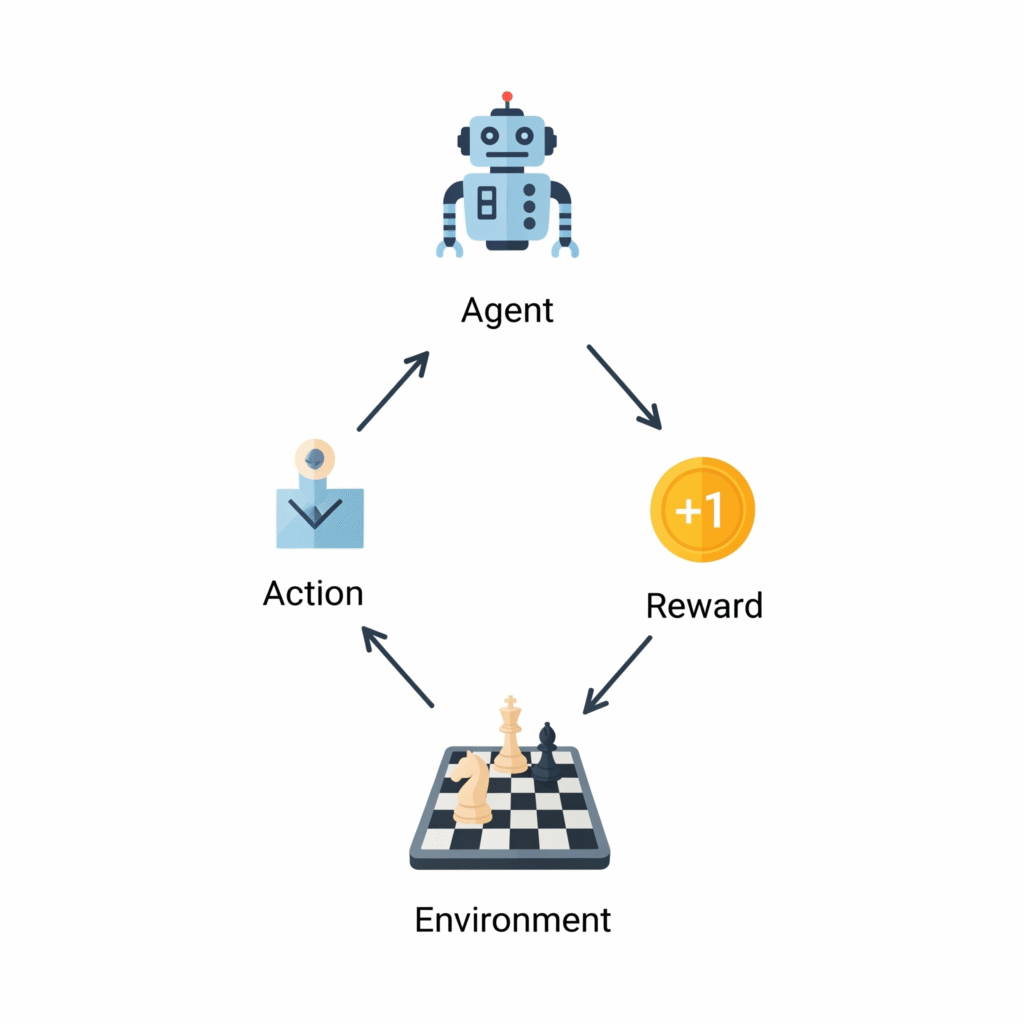
1. El Agente (El que Aprende)
- El Agente: Es el que aprende. En nuestro caso, el niño. En el caso de AlphaGo, el programa de IA.
2. El Entorno (El Mundo de Juego)
- El Entorno: Es el mundo con el que el Agente interactúa. Para el niño, es la calle con su bicicleta. Para AlphaGo, es el tablero de Go.
3. La Acción (La Decisión)
- La Acción: Es cualquier movimiento que el Agente puede realizar. Girar el manillar, pedalear, o colocar una piedra blanca o negra en el tablero.
4. La Recompensa (La Única Señal para Aprender)
- La Recompensa: ¡Esta es la clave de todo! Es la única señal que recibe el Agente. No se le dice «giraste el manillar demasiado a la izquierda». Solo se le da una puntuación. Para el niño, avanzar es positivo, caerse es negativo. Para AlphaGo, la recompensa era aún más simple: al final de la partida, recibía un +1 si ganaba y un -1 si perdía. Nada más.
El Caso AlphaGo: Cómo la IA Dominó el Juego Más Complejo
La Clave del Éxito: Millones de Partidas contra Sí Misma
Aquí es donde la historia se vuelve asombrosa. ¿Cómo puede una IA aprender un juego tan complejo con una señal de recompensa tan simple? La respuesta es la escala.
Ahora, imaginen a nuestro niño aprendiz. Pero con superpoderes:
- No se cansa.
- No siente dolor por las caídas.
- Puede intentar aprender a montar en bicicleta un millón de veces por hora.
Después de millones de intentos, no solo aprendería a montar en bicicleta, sino que probablemente podría realizar acrobacias que desafiarían la física. Habría explorado todas las combinaciones posibles de acciones y resultados hasta encontrar la estrategia óptima.
Eso es exactamente lo que hizo AlphaGo. Jugó millones de partidas de Go contra sí mismo. Al principio, sus movimientos eran torpes y aleatorios, como los del niño que cae una y otra vez. Pero con cada partida (cada ciclo de intento-recompensa-ajuste), su estrategia se refinaba. Descubrió patrones y tácticas que ningún humano había concebido en los 3,000 años de historia del juego.
Aplicaciones Futuras: Robots que Aprenden a Caminar
Este tipo de aprendizaje no se limita a los mundos virtuales de los juegos. Es la principal esperanza para la robótica. ¿Cómo enseñas a un robot a caminar sobre un terreno irregular o a tomar un objeto frágil sin romperlo? Es muy difícil escribir un manual de instrucciones para eso.
En su lugar, los ingenieros utilizan el Aprendizaje por Refuerzo. Dejan que el robot, en una simulación, intente caminar. Cada vez que da un paso sin caerse, recibe una pequeña recompensa. Cada vez que cae, un pequeño castigo. Después de millones de intentos simulados, el robot desarrolla una estrategia de movimiento robusta que luego puede aplicar en el mundo real.
Conclusión: La IA como Exploradora por Experiencia
El Aprendizaje por Refuerzo es la IA en su forma más pura y exploratoria. No es un erudito que ha leído una biblioteca, sino un aventurero que ha aprendido a navegar un territorio desconocido a base de experiencia directa. Es el espíritu del juego, la curiosidad y el descubrimiento, encapsulado en un algoritmo.
Fuentes y Recursos Recomendados:
- DeepMind Blog: «AlphaGo: How it works» – El blog de los creadores de AlphaGo explicando los principios detrás de su extraordinario éxito. Enlace al blog de DeepMind.
- «AlphaGo – The Movie» (YouTube) – Un documental galardonado que narra la emocionante historia del enfrentamiento entre Lee Sedol y AlphaGo. Es una visión humana y conmovedora de este hito de la IA. Enlace al documental en YouTube.
- Harvard Business Review: «Reinforcement Learning, Explained» – Un artículo que explica el concepto de RL en un contexto de negocio, de una manera muy clara y concisa. Enlace a HBR.